

大语言模型在肺癌诊疗中的应用进展、伦理困境与展望
1. 四川大学华西医院 胸外科(成都 610041)
胸外科(成都 610041)
2. 四川大学华西临床医学院(成都 610041)
3. 四川大学计算机学院(成都 610065)
通信作者:陈楠,Email:dr.chennan@wchscu.cn;蒲强,Email:puqiang100@163.com
关键词:大语言模型;肺癌诊疗;人工智能;伦理规范;临床决策支持;医学信息学
引用本文:任治臻,郗宇凡,朱旭,等. 大语言模型在肺癌诊疗中的应用进展、伦理困境与展望. 中国胸心血管外科临床杂志, 2026, 33(2). doi: 10.7507/1007-4848.202509019
Ren ZZ, Xi YF, Zhu Xm, et al. Application advances, ethical dilemmas, and future directions of large language models in lung cancer diagnosis and treatment. Chin J Clin Thorac Cardiovasc Surg, 2026, 33(2). doi: 10.7507/1007-4848.202509019
摘 要
肺癌是全球发病率和死亡率最高的恶性肿瘤之一,肺癌诊疗工作量大,如何高效、精准地处理日益复杂化的医疗信息,是目前肺癌诊疗过程面临的挑战。近年来,大语言模型(large language models,LLMs)凭借其强大的自然语言处理能力,在处理复杂医疗数据方面展现出独特优势,在肺癌诊疗领域的应用价值不断攀升。本文系统分析LLMs在肺癌辅助诊断、肿瘤特征提取、自动分期、进展及转归分析、治疗建议、文书生成、患者教育领域展现出卓越的潜力;同时面临在复杂综合决策(如TNM分期、个性化治疗建议)中的性能不稳定与“黑箱”问题,以及训练数据偏见、模型幻觉、数据隐私与跨语种适配(“数据殖民”)等严峻的技术伦理挑战。未来着重构建高质量肺癌专病多模态语料库、开发可解释与合规的专科模型,并与现有临床工作流无缝整合。在技术创新与伦理规范的双驱动下,审慎推进LLMs应用于肺癌全流程管理,实现肺癌诊疗高效化、标准化和个性化。
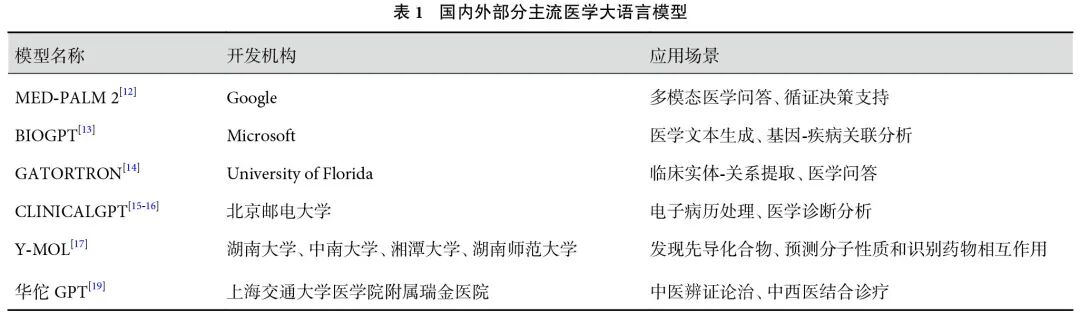
1
大语言模型在肺癌诊疗中的应用
1.1 大语言模型辅助肺癌诊断
LLMs的逻辑分析与综合处理能力赋予了LLMs结合影像学辅助肺癌诊断的应用途径,可为医生提供诊断参考意见,促进肺癌诊疗效率提升。2024年一项韩国多中心研究[20]使用未训练的Google Gemini Pro 1.0、ChatGPT-3.5和GPT-4从1 800份非结构化的胸部X线片和CT报告中诊断肺癌等7种肺部疾病。三种模型诊断肺癌的准确率均为0.90,其中GPT-4诊断肺癌的敏感度为0.97,有辅助筛查肺结节的潜力。首都医科大学Liu团队[21]提出了一种结合特征摘要(F-sum)、CoT和检索增强生成(RAG)的提示工程策略,以提高三种LLMs(GLM-4-Plus、GLM-4-air和GPT-4o)通过CT报告鉴别诊断肺部疾病的能力。采用该方法的GLM-4-Plus在测试集上取得了最优表现(F1分数0.89、准确率0.89),而GPT-4o在外部验证集上诊断性能最优(F1分数0.86、准确率0.92)。
肺结节报告分级系统(Lung-RADS)是肺癌筛查中广泛应用的肺结节良恶性分类标准[22]。美国堪萨斯城大学Kabakus团队[23]测试了LLMs利用CT报告进行Lung-RADS风险判断的能力,GPT-4o判断Lung-RADS评分的准确率最高(0.836),优于ChatGPT-3.5(0.701)、Gemini(0.709)。而中国医科大学Song和Zhang团队[24]的研究利用预训练GPT-4o分析了647例患者的纵向CT随访图像,评估了肺结节恶性概率、结节大小和特征的动态变化,为动态监测肺结节演变趋势提供了新思路。结果显示,GPT-4o融合三次以上随访图像后预测肺结节恶性程度的平均诊断准确率达0.88,且对结节大小的测量值与手动测量的平均相关系数为0.91,六位放射科医生均高度评价了GPT-4o捕捉结节特征变化的能力(量表评分4.17/5)。以上研究表明,经过优化的LLMs在肺癌诊断中潜力巨大,能够有效提升诊疗效率并获得临床医生的认可。
1.2 大语言模型辅助肺癌特征提取
LLMs通过解析影像学报告、电子健康记录等非结构化文本,可实现肺癌关键参数特征的提取,辅助医疗数据结构化。杭州之江实验室Hu团队[25]发现零样本学习的ChatGPT在从CT报告中提取肿瘤位置、长径及短径的准确率达0.985、0.980及0.973。在提示中加入先验知识后,ChatGPT对肿瘤毛刺征、分叶征和胸膜侵犯的提取性能提高(准确率0.986、0.976、0.935),但对肿瘤密度和淋巴结情况的提取性能没有明显改善(准确率0.963、0.923)。日本Yamagishi团队[26]采用ELYZA模型提取了Medtxt-RR数据集中135份胸部CT报告的肺癌特征,结果显示提取肿瘤大小的准确率为0.733,肿瘤位置的准确率为0.83。华盛顿大学Bhattarai团队[27]比较了多种模型从电子健康记录提取非小细胞肺癌(non-small cell lung cancer,NSCLC)特征的性能,结果显示,GPT-4识别肿瘤分期(F1分数,精确率,召回率分别为0.92,0.93和0.91)、手术方式(0.92,0.95和0.89)、肿瘤复发(0.96,0.94和0.98)和复发器官(0.68,0.67和0.70)的性能优于其他模型。综合来看,LLMs从大量非结构文本中提取肺癌特征的能力可显著减轻数据结构化处理的工作量,但仍需要人工审核作为质量保障。
1.3 大语言模型辅助肺癌自动分期
LLMs可利用患者影像学或病理报告进行肺癌自动智能分期,对于提升肺癌分期的效率和标准化程度具有重要意义。在基于影像学报告进行自动肿瘤分期方面,韩国峨山医院Jeong团队[28]基于700例NSCLC患者的胸部CT或FDG PET/CT报告的研究发现,GPT-4o进行TNM分期的准确率高于GPT-4和ChatGPT-3.5(0.741 vs. 0.701 vs. 0.574),与住院医师水平相当(0.777),但不及资深专家(0.854)。日本神户大学Matsuo团队[29]评估了零样本学习的 ChatGPT-3.5-turbo从162份肺癌胸部CT报告中判断分期的能力,发现模型对T、N和M分期判断性能存在显著差异,N和M分期判断准确率较高(N:0.80,M:0.94),而T分期判断准确率较差(0.47),TNM综合分期准确率仅0.36。该研究还发现针对日语CT报告的分期性能低于英语报告,突显了其潜在的语言依赖性缺陷。然而,通过引入先进架构,LLMs的分期性能显著提升,日本山梨大学Johno团队[30]开发了RAG架构的NotekLM,在基于肺癌CT报告进行自动分期任务中表现出0.86的准确率,优于参照模型GPT-4o的0.39(使用RAG)和0.25(不使用RAG)。以上研究表明,LLMs可提高使用CT报告标记肺癌分期的效率和标准化程度,但需警惕生成的T分期的准确性。
在基于病理报告进行自动肿瘤分期方面,美国得克萨斯大学Xie团队[31]收集了1 024条TCGA、CDSA数据库的肺癌病理报告,评估ChatGPT-3.5-Turbo-16k模型在判断肺癌TN分期和病理诊断(肺腺癌、肺鳞状细胞癌、其他)的能力。该模型在判断病理诊断的能力优秀(准确率0.99、F1分数0.99),但评估整体分期的准确率仅为0.76(T分期准确率0.87、N分期准确率0.91)。韩国首尔国立大学Chung团队[32]比较了多个模型从29914份肺癌病理报告中判断TN分期的能力。微调后的Llama-2-7B(Orca-2)和Mistral-7B(Dolphin)模型判断TN分期的准确率达0.986、0.9876。该团队进一步[33]在3216份肺癌患者的手术病理报告验证,CoT微调的Orca-2-13b模型所判断的TN分期与医生标注的精确匹配率为93.4%,且对报告内容的理解达到了较高水平(语义匹配率86.4%)。综上, LLMs为基于病理报告的肺癌分期提供了较为高效的解决方案,当前的错误主要来源于模型缺乏系统性的病理学背景知识[31]以及对提示的理解不准确[32]。
1.4 大语言模型辅助肺癌进展及转归分析
LLMs可根据患者多次检查报告对肺癌进展情况进行分类,从而为临床决策调整和精准治疗提供支持。丹娜法伯癌症研究院Elmarakeby团队[34]纳入了1 112例肿瘤患者的14 218份影像报告,使用9种模型(如BERT、Longformer等)进行肿瘤进展(恶化、稳定、缓解)评估,其中DFCI-ImagingBERT识别癌症缓解和恶化的能力最佳,曲线下面积(AUC)分别达到0.94和0.95。Fink团队的一项研究[35]则利用提示工程引导GPT-4和ChatGPT对424例肺腺癌、肺鳞癌、肺小细胞癌患者的CT报告实现肿瘤进展评估(恶化、稳定、缓解),发现与ChatGPT相比,GPT-4表现更好(准确率0.972 vs. 0.942,F1分数0.96 vs. 0.91),在病情解析的主观评分上,GPT-4能够输出符合事实(事实正确性评分4.3 vs. 3.9),更切合提问(准确性评分4.4 vs. 3.3)的文本,且输出无依据结果的可能性更小(幻觉率1.7% vs. 13.7%)。此外,纪念斯隆凯特林癌症中心(MSK)和加州大学旧金山分校(UCSF)合作开发了一个开源的Woollie模型(Woollie MSK)[36],可基于影像学报告判断肺癌进展情况。Woollie MSK模型在MSK和UCSF数据队列中判断肺癌进展情况的AUC值达0.96和0.95,凸显了其在癌症进展分析方面的潜力。
此外,东京大学Yasaka团队[37]验证了经3 111份CT报告训练的tohoku-BERT,对4种肺癌治疗情况(无肺癌、肺癌确诊未处理、肺癌治疗后、肺癌计划放疗)进行判断的能力。微调后的该模型总体判断准确率略高于两位放射科医师(0.983 vs. 0.969、0.969),且完成时间更短。综上,LLMs可较好地满足肺癌治疗情况与转归情况判断分类的需求,为标准化评估肿瘤疗效提供了可行的思路。
1.5 大语言模型辅助肺癌治疗建议
在肺结节治疗建议方面,耶鲁大学Moore 团队[38]利用26 545份急诊科胸部CT报告训练RoBERTa-base模型以识别偶发肺结节,并对高危肺结节给出不同随访建议。在1 000例测试报告中,模型给出随访建议的能力展现出临床可用性(精确率0.82,召回率0.90,F1分数0.85)。对于检查发现良性结节的患者,模型建议随访的准确率达0.933。此外,Zabaleta团队[39]利用最新西班牙SEPAR肺癌治疗指南[40]指导的ChatGPT-3.5-turbo,回顾性分析52例NSCLC患者病历摘要并生成五类治疗建议(随访观察、手术、放疗、化疗、放疗+化疗)。ChatGPT-3.5-turbo和临床专家的总体意见一致性为76%,对是否手术的决策一致性达92.3%。对于TNM分期明确的患者,ChatGPT-3.5-turbo的建议准确率提高了43.5%(30/33 vs. 9/19)。然而,加拿大不列颠哥伦比亚大学Gamble团队的研究则对 LLMs指导肺结节管理临床实践的可行性提出警示,该团队[41]开发了Fleischer指南微调的ChatGPT、GPT-4模型及指南和随访建议同时微调的ChatGPT,并依据Fleischer指南中的不同肺结节类型制定了120份虚拟CT报告,验证微调后的三种模型基于CT报告生成治疗建议的效果,研究发3种LLMs仍表现不佳(准确率0.42 vs. 0.66 vs. 0.46),且从未正确推荐是否行PET/CT或活检。
在晚期肺癌综合治疗建议方面,美国Brown团队[42]的研究证实经提示和NCCN指南微调的GPT-4所提供的晚期肺癌首选化疗方案与NCCN指南的一致性很好(定性评估分数23/24),优于基准模型(17/24)。而一项德国的研究[43]纳入具有基因变异的晚期肺癌病例,对比了4个LLMs和临床专家对于肿瘤靶向治疗的建议,结果显示4个LLMs综合提出的治疗方案质量不佳,无关信息多且有很多重要信息遗漏(F1分数、精确率、召回率均为0.29)。但值得注意的是,LLMs提供了两项被临床专家忽略的有效治疗方案。这表明尽管当前LLMs还无法替代临床专家,却可以作为一种辅助工具补充治疗策略。
在肺癌放疗靶区的划分方面,霍普金斯大学Ding团队[44]开发了电子病历指导的肺癌自动分割放疗框架,借助LLMs识别真实病灶的位置、大小和淋巴结浸润,指导3D分割模型检测和分割肺结节,可辅助提高分割精度(与金标准重合70%以上的平均综合表现mAP@IoU:59.15/100分)和分割结果可靠性(与金标准重合度Dice指数0.97),并缩短放疗靶区的划分时间。在肺癌放疗计划生成方面,Wang团队[45]联合多中心合作开发了GPT-plan,通过学习既往放疗计划,可模拟放疗剂量师和医学物理师的协作流程,根据预定义的框架生成高质量放疗计划。GPT-plan生成的计划靶区覆盖率高(目标区域覆盖程度指标D95增加4.75%,P<0.05;适形指数CI降低4.55%,P<0.05)、均匀性好(剂量同质性指标HI降低49.52%,P<0.05),优于目前最先进的自动规划方法(ECHO),且在危及器官保护方面表现不劣于ECHO方法(平均辐射剂量GPT-plan vs. ECHO:食管0.95 Gy vs. 0.86 Gy、心脏0.95 Gy vs. 0.94 Gy、肺4.37 Gy vs. 5.10 Gy)。
在肺癌术后护理建议方面,哥伦比亚大学Santos团队的一项研究[46]聚焦于利用提示工程让ChatGPT遵循自定义的患者需求框架(patient's needs framework)为老年肺癌患者制定高质量的护理计划。该团队发现,在尝试输入1例虚拟的老年肺癌患者的基本情况后,ChatGPT能够生成与临床专家提出的护理计划类似的高质量护理计划,且可针对涉及的措施逐一提供解释,展现了LLMs作为优化癌症护理计划的决策支持工具的潜在价值。
以上研究表明,目前LLMs已在部分肺癌治疗的临床场景中实现了较好的效果,但LLMs辅助肺癌临床治疗建议仍存在一定风险,未来可针对特定临床场景开发专科化LLMs,优化决策相关性和简洁性。
1.6 大语言模型辅助肺癌文书生成
LLMs可根据影像所见自动生成影像学报告的总结意见,有望减轻放射科医生阅片的工作量[47]。一项中美学者合作的研究[48]利用包含约6万例胸部X线片报告的MIMIC-CXR数据库评估了29种LLMs生成总结意见的能力,结果显示Claude2、PaLM2和BayLing-7B分别通过零样本、单样本和五样本学习后生成的文本在信息完整性上表现最佳(Recall@L指标分别为0.256、0.225、0.275)。而北京大学肿瘤医院团队[49]则比较了3个国产LLMs和6个国外LLMs在生成中文CT、PET/CT和超声的报告总结意见的能力,发现ERNIE Bot、通义千问和Claude分别在处理CT、PET/CT和超声报告时表现最佳,体现在措辞精准性(BLEU最高0.483、0.469、0.420),结论完整性(ROUGE-L最高0.495、0.361、0.561)和语义正确性(METEOR最高0.498、0.463、0.520)上表现最佳。威尔康奈尔医学院Ong团队[50]首次报道了GPT-4可用于生成胸部CT总结意见,在3位放射科医生的主观量表评估中,其在连贯性、全面性、事实一致性以及影响危害性4个维度均劣于人工撰写的总结意见(P<0.001)。总体而言,不同LLMs在影像报告的意见总结任务中性能差异大,且在多个评价维度上仍与临床医生书写的总结意见有较大差距[48-50]。
在病历文书的生成方面,得克萨斯大学、耶鲁大学和梅奥医疗中心合作探究了LLMs在撰写出院记录的作用[51]。结果显示GPT-4生成的出院记录在相关性(平均量表评分4.95/5分)和事实准确性(4.40/5分)方面得分最高,而GPT-4o在完整性(4.55/5分)方面表现最佳。GPT-4o 和 LLaMA3生成的出院记录较好地保留了手写出院记录中的语义内涵(语义相似度0.83、0.837),展示出LLMs在生成病历文书方面的潜力,可有效减轻医生文书工作压力。同样,四川大学华西医院自主研发的“华西黉医”大模型[52],在辅助生成出院记录方面展示出不错的能力,可将每份病历书写平均时间由21 min 缩短至5 min,效率提高3.2倍,系统输出准确率 92.4%。此外,台湾阳明交通大学Wang等[53]开发了一套代理检索增强生成(Agentic RAG)系统,利用公开的LLMs进行肿瘤诊断编码自动登记(F1分数0.824),证实了提示工程优化的LLMs有潜力提高肿瘤病例登记的效率和准确性。
1.7 大语言模型辅助患者医学教育
LLMs能基于其LLMs强大的交互能力为患者提供详细且个性化的解答,帮助患者理解复杂的疾病信息。加利福尼亚大学洛杉矶分校的学者[54]创建了肺癌预防、筛查及常用术语相关的40个非专家问题,并由3名测试人员提问,ChatGPT-3.5回答问题的准确性(OR=1.55,P=0.004)和3次回答的一致性(OR=6.65,P=0.002)优于Google Bard,但所有模型均未提供100%正确且3次均一致的回答。另一方面,Gencer等[55]使用9种可读性指标评估ChatGPT回答肺癌定义、诊断、治疗等80个问题的可读性,结果显示ChatGPT生成的回答可读性仅达中等水平(Gunning fog指数均值13.63),难以适配不同教育水平的人群。马里兰大学医学院Jeudy研究团队[56]尝试使用ChatGPT、GPT-4和Bard进一步优化ChatGPT初步输出的回答,尽管Bard优化后的回答的文本复杂度最大可降低至Flesch-Kincaid 年级水平8.2级(即大部分美国8年级学生能轻松理解的水平),但仍未达到美国医学会为患者医学教育材料推荐的6年级可读性标准。
此外,基于LLMs的文本理解能力,LLMs有望进一步解释专业性强的医疗报告,柏林慈善大学医学中心[57]评估了ChatGPT解释肺癌PET/CT报告并回答PET/CT相关问题的能力,发现其92%的回答被评价为适当(符合临床标准),96%的回答被评价为有用(信息具体且相关)。德国慕尼黑大学医院Jeblick团队[58]成功利用ChatGPT简化和解读影像学报告至5岁儿童的阅读水平,同时保证事实正确性、完整性和无潜在危害。维克森林大学Whitlow团队[59]一项类似研究利用LLMs简化138份肺癌脑转移患者原发灶和转移灶的影像学报告,发现由GPT-4简化的报告专业术语使用减少,篇幅更短且更易于理解(总体得分4.268/5)。
2
总结与展望
2.1 在临床落地可靠性方面的挑战
面对日益复杂化的医疗信息,将LLMs从前沿研究推向可靠的临床应用,已成为提升诊疗效率的迫切需求。本文回顾了LLMs在肺癌诊疗各环节中的应用潜力,在肺癌诊疗的单一细分任务中,如肺癌特征信息提取、肿瘤治疗及进展分类、肺癌放疗及护理治疗建议、病历文书生成、提升报告可读性等方面,LLMs表现出良好的性能,一定程度上等同于临床专家。然而,目前LLMs在一些临床应用方面可靠性不足,依然是当前LLMs临床落地转化的核心瓶颈,极大限制了LLMs在临床上的使用与推广。
首先,医生对于LLMs临床落地可靠性的担忧来源于LLMs性能的不稳定以及LLMs和临床专家的矛盾结论。在复杂临床情境的综合决策中,如基于报告的TNM自动分期、辅助肺癌诊断、给予肺癌治疗建议等方面,LLMs临床应用的局限性依然突出,且与临床专家结论可能矛盾,例如Gamble团队指出LLMs指导肺结节管理临床实践相较于临床专家表现不佳,Benary团队也指出LLM指导晚期肺癌基因治疗方面无法替代临床专家[41,43]。这些矛盾揭示出,综合决策往往需要跨领域的知识整合和个体化情境适应,而这些依赖主观经验与情感认知的能力仍是当前LLMs亟待解决的难题。
其次,LLMs临床落地的挑战来源于模型幻觉和“黑箱”问题。幻觉会导致LLMs生成无依据的错误结论,对临床决策构成潜在风险[60]。尽管近年来LLM技术的发展一定程度上改善了幻觉问题[57,61],但仍无法杜绝。同时,“黑箱”问题使得LLMs的决策过程缺乏可解释性,尤其是在涉及肺癌诊断、治疗策略制定等高风险决策时,医生难以完全信任LLMs输出的结果。
最后,LLMs临床转化的进程还受限于支撑其可靠落地的外部环境的不成熟。一方面,真实世界的肺癌数据具有高度复杂性和异质性,不同数据集的文本表述不一、数据指标不一,罕见病例样本稀少,这些都可能导致LLMs产生偏见,影响模型处理任务的准确性[60]。另一方面,当前研究多采用主观评分及BLEU、ROUGE等文本指标作为评估工具,缺少统一、标准化的性能评价体系,使得不同研究的结论难以横向比较。
2.2 提升临床落地可靠性的方向
展望未来,推动LLMs在肺癌诊疗领域的深度研究与审慎应用,必须围绕提升其临床可靠性展开。首先,应进一步探索性能优化策略。本文综述多项研究表明,使用指南等医学资料或优化的提示工程进行微调的LLMs相较于零/少样本学习的LLMs的性能更好。同时,CoT和RAG技术也被证明对LLMs的医学推理能力也有较好的提升。未来肺癌LLMs的开发需结合算力资源选择最高效的训练策略,释放LLMs潜力并控制模型幻觉的产生。
其次,应探索多模态融合技术,整合患者的影像、病理、电子病历等多源数据。目前肺癌诊疗LLMs主要利用CT报告和病历作为数据来源,而多模态LLMs能够整合患者多维信息[62-63],从而实现对患者健康状况的全面监测。例如在肺癌筛查中,利用多模态模型联合分析CT影像、电子病历及检验结果,能够更全面地分析肺结节恶性及生长的概率,从而精准制定后续随访策略。
此外,尽管LLMs已在肺癌诊疗的多个关键节点展现出应用潜力(图2),但要将其转化为真实的临床效用,与现有工作流的整合是必须跨越的挑战。目前,LLMs的应用整体仍处于探索阶段,只有极少数模型能真正嵌入医院信息系统(HIS)。面对大部分医疗机构算力资源不足、维护成本高昂的现状,优化模型的轻量化设计成为必然选择,这不仅能降低部署、维护及更新的成本,也更易于在真实医疗场景中进行大规模验证并持续更新,最终实现其临床适用性。
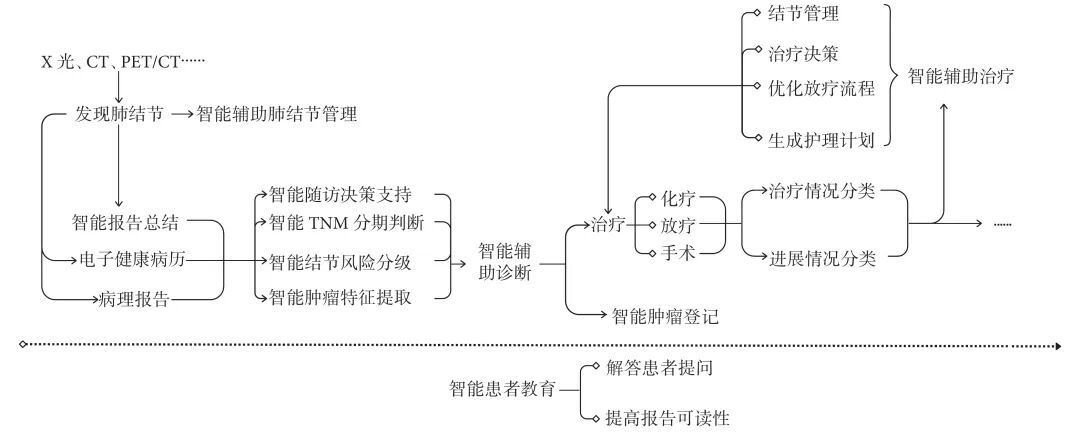
图2 大语言模型服务肺癌诊疗流程图
最后,亟需构建多模态、多语种、代表性强、标记准确的肺癌专科数据集。并且在大规模数据集的基础上,探索制定包含诊断准确性、临床实用性及伦理合规性的多维评价体系,客观一致地衡量模型性能。例如近期发布的基于LLMs的临床预测模型研究报告指南[64](TRIPOD-LLM),便是首个专门针对基于LLMs构建预测模型研究的综合性报告框架,旨在提升LLMs医学研究报告质量和透明度,促进LLMs规范、伦理地融入医疗领域。
2.3 技术伦理挑战
随着LLMs在肺癌诊疗领域的应用日益深化,其潜藏的严峻技术伦理困境也愈发凸显,包括当模型输出错误回答时的责任主体模糊性、由英文语料库主导模型训练引发的“数据殖民”风险,以及贯穿始终的患者数据隐私与安全问题。
首先,当LLMs生成错误的诊断或治疗建议时,其责任尚无清晰法律界定[65]。LLMs既不同于完全人为操控的传统医疗器械,又区别于具有自主意识的人类医生。算法开发者、医疗机构和最终采纳建议的临床医生均与LLMs的诊疗行为相关联,而LLMs的“黑箱”特性导致决策不可追溯,难以明确各方的责任边界。
其次,当前高性能LLMs主要基于英文语料库训练,将其直接应用于中文肺癌诊疗场景时,可能存在“数据殖民”风险[66],即模型在中文任务中存在显著性能偏差[37,49],无法完全适配我国肺癌患者的临床特征与诊疗路径,造成潜在的偏见。此外,国外LLMs不可避免嵌入了西方价值观念和文化立场,形成数字时代的新型安全威胁。
最后,隐私保护在LLM训练和用户交互中至关重要。通常,训练LLMs需要海量的真实世界医疗数据,用户在使用LLMs时也可能无意识暴露敏感数据,这引发了LLMs数据隐私安全的担忧[67]。一方面,LLMs将患者数据上传至外部服务器的过程显著增加了数据泄露的风险。另一方面,模型在数据整合与关联推理时可能会将数据中散在的隐私信息关联到个体身份,使得传统的匿名化保护措施面临失效风险。
2.4 规范技术伦理的方向
展望未来,推动LLMs在肺癌诊疗领域的可持续发展,必须以伦理规范作为信任的基石。首先,需建立系统化法律框架与责任分担机制。目前,欧盟《人工智能法案》基于人权保护原则将医疗AI列为“高风险系统”,要求开发者承担算法透明度义务并负主要责任[68],我国现行的《人工智能医用软件产品分类界定指导原则》将人工智能医用软件依据其是否用于辅助决策,分别按照第三类、第二类医疗器械进行管理[69],但仍需进一步完善相关法律法规,明确动态诊疗场景中的责任主体边界。
其次,需加快国内LLMs技术的开发应用,把握医疗自主权,以自主可控的技术抵御“数据殖民”风险。同时,开发在开发LLMs过程中,需建立监督机制,确保LLMs在内容输出方面与中国主流价值观念对齐。
最后,LLMs需严格遵循法律伦理要求保护患者隐私,在训练过程中实施访问控制、数据脱敏等措施降低数据泄露风险,同时加强LLMs在隐私保护方面的审查。
3
小结
尽管当前LLMs在肺癌领域的应用仍面临诸多挑战,但随着技术的持续迭代、数据的不断积累、多学科协作的日益深化以及评价体系的逐步完善,LLMs有望在肺癌全流程管理中发挥更重要的作用,推动肺癌诊疗向高效化、标准化和个性化的方向发展。在部署LLMs作为临床决策支持系统之前,必须仔细评估其临床落地可靠性和潜在的技术伦理风险,制定适当的监管措施,以确保LLMs的安全性和有效性。
利益冲突:无。
作者贡献:任治臻负责文章的选题和设计,拟定研究思路;任治臻、郗宇凡和朱旭完成文献资料收集与整理、初稿撰写;罗逸杰、黄格婷、宋俊樵参与文章设计;任治臻、郗宇凡、陈楠参与论文修改;徐修远和蒲强对文章关键结论进行修改;全体作者最终定稿,确保论文的准确性并对论文承担责任。
参考文献略。
作者介绍
通信作者 蒲强

主任医师、博士生导师。四川大学华西医院胸外科主任、胸部肿瘤研究所副所长,第一届国家优秀青年医师。担任中国抗癌协会胸壁肿瘤专业委员会副主任委员、中国医药教育协会肺癌医学教育工作委员会第二届常务委员、四川省医学会胸心外科专业委员会副主任委员、四川省国际医学交流促进会终末期肺病多学科全程诊疗(MDT)专业委员会主任委员、四川省预防医学会胸部肿瘤多学科分会主任委员、四川省医学会器官移植专业委员会委员、四川省医师协会机器人外科医师分会常务委员、成都市医学会胸心外科专业委员会候任主任委员、成都市抗癌协会肺癌诊疗一体化专业委员会主任委员、哈佛医学院访问学者。长期聚焦“肺癌、终末期肺病的治疗和发病机制研究”。实施全球首例胸腔镜肺移植、首例右肺劈裂翻转肺叶移植。以第一或通讯作者在 Ann Thorac Surg、Int J Surg 等权威期刊发表论文 30 余篇。为改善肺移植预后,研究肺再生分子机制,以第一或通讯作者在 Cell Metab、Sci Transl Med 发表论文 3 篇。主持纵向课题 5 项,累计经费 395 万。作为主要作者编写国内外共识 4 项、书籍 3 部。授权专利 7 项。获中华医学科技奖一等奖、四川省科学技术进步奖一等奖。
第一作者 任治臻

四川大学华西临床医学八年制创新班博士研究生,中共党员,主要研究方向为肺癌诊疗大语言模型。作为核心人员参与国家科技重大专项,四川省科技厅项目,医院1.3.5人工智能项目等多项科研课题,发表论文4篇,授权发明专利3项,受理发明专利2项,曾获“全国大学生生物医学工程创新设计竞赛二等奖”、“四川大学自立-志东奖学金”、“四川大学综合一等奖学金”等荣誉。
审校:Faline
排版:Faline
执行:Faline
医脉通是专业的在线医生平台,“感知世界医学脉搏,助力中国临床决策”是平台的使命。医脉通旗下拥有「临床指南」「用药参考」「医学文献王」「医知源」「e研通」「e脉播」等系列产品,全面满足医学工作者临床决策、获取新知及提升科研效率等方面的需求。
本平台旨在为医疗卫生专业人士传递更多医学信息。本平台发布的内容,不能以任何方式取代专业的医疗指导,也不应被视为诊疗建议。如该等信息被用于了解医学信息以外的目的,本平台不承担相关责任。本平台对发布的内容,并不代表同意其描述和观点。若涉及版权问题,烦请权利人与我们联系,我们将尽快处理。
